Home
/ Blog /
From Support Chats to a Searchable FAQ: How We Used ChatGPTFrom Support Chats to a Searchable FAQ: How We Used ChatGPT
January 17, 20235 min read





Share




Customer support is a key part of building a successful product. At 100ms, we use Slack and Discord to connect with our customers. As the number of support queries grew with usage, we could foresee it becoming challenging to handle in the future. To address this proactively, we decided to create a list of all questions asked across our conversations, along with the responses we gave. This made our customer success team more efficient by reducing the time spent answering repetitive queries. Additionally, we also added a FAQ section in our external docs, allowing our customers to quickly find answers without the need to reach out to us. This further allowed our team to focus on more complex issues and provide even better support.
But how do you create such a comprehensive list from customer conversations scattered across multiple channels? This is where ChatGPT comes in. We broke the problem into two parts, extracting conversations from Slack and then feeding them to ChatGPT.
Extracting Conversations
Before we go ahead with making ChatGPT part of our customer success team, we need to extract messages exchanged across all our Slack channels.
Our first attempt to do this was to use Slack's inbuilt text export but it didn't work as the messages were organized by when they were sent. For example, imagine two different threads discussing two separate topics at the same time. If we order them by their timestamps, the messages from these two threads would get intermixed, losing the context in which they were present. We needed a text file that preserves the order of the conversations in their respective threads.
We already had a Slack Bot in place which we use for different tasks, so it made sense to add a new command in it for this purpose. Below is a sample of how the end result looked. Slack allows a bot to have access to all previous conversations in a channel as long as the bot is part of the channel. We made a new command to extract the conversation as a text file.
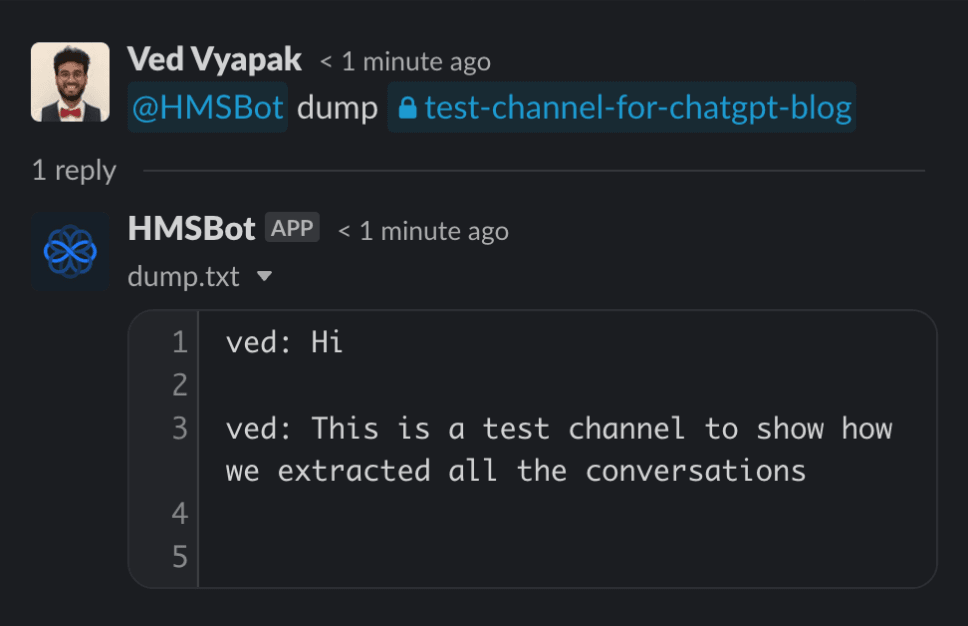
As for the implementation details, Slack’s API made this quite easy. There is a conversation history method to get all top-level messages in a channel. This doesn’t give the messages within a thread though, so we had to also use the conversation replies API for fetching messages which had a thread attached to them. We kept the messages within a thread together in the final dump to keep the text contextual. We also filtered out generic messages like those for people joining and leaving the channel. A sample of how the result dump looks like -
ved: can I record a room from the SDK?
tushar: yes, the JS SDK has a startRecording method you can check here in the docs
ved: is it possible to change the resolution?
tushar: (replying in thread) yes, the function takes an optional config with field for resoltuion
ved: (within thread) that works, thanks!
ved: how can I switch between HLS and WebRTC?
tushar: switching between two can be easily done via changing the participant's role, more details here
...
...
...
Feeding to ChatGPT
Now that we have a history of conversations, we proceeded with handing it over to ChatGPT. Our goal was to extract a list of all questions and answers which were discussed. In the first pass, we went with giving the full text but soon realised that we were running into limits of how much data it can process in one go. For a file containing over 1400 lines of conversations, we got back only 10 questions and answers. We figured out that ChatGPT was only processing the initial part of the text and there is a limit on both the input and output.
So what do we do now? Well as you can guess, we went for dividing the whole conversation into smaller batches of 100 lines each. This approach proved to be successful, resulting in the generation of better quality questions and answers.
We experimented with different prompts to extract this information. We found that though ChatGPT was able to assess the questions quite well from the context, it was at times making up some part of the answers. This was not a big issue though and was corrected via manual review with the Customer Success team’s help later.
An example of the prompt we used -

An example reply from ChatGPT from an attempt to generate a list of questions and answers that were asked in a conversation chunk -

We applied this process to more than 50 Slack channels that had an extensive conversation history. The results were then compiled into a Google Sheet resulting in a knowledge base of around 250 questions and answers.

Final Refinement
Once we had the compiled list in place, our Customer Success and Product team took over the review process. This involved -
- removing incorrect responses, rewording correct answers as needed
- framing some questions in a better way
- adding more details like links to our docs and blogs
- grouping the questions into different categories
- merging similar-looking questions
- generating a list of FAQs for common themes to put in our docs
Wrapping Up
The initial momentum required to take on a huge task is often intimidating, causing delays despite the task's importance. This was the case for us as well, with the idea of creating FAQs being discussed for multiple months without any progress. While the raw responses from ChatGPT were suboptimal, its use was extremely important. The final output we ended up with could not have been achieved without its help, certainly not in a short time frame.
As we continue to improve customer success, there are a few more things we plan to do on top of the above questions and conversation histories. An idea currently being experimented with is to build a bot that can respond directly to queries on Slack and Discord if it finds a match based on vector embeddings. We'll be writing more about this in a future post.
If you have any questions or suggestions for us, feel free to head over to our Discord.
Engineering
Related articles
See all articles